来源:《基于UNIX/Linux的C系统编程》、《操作系统教程(第4版)》、《LPI LINUX认证权威指南(第二版)》
并发进程之间的交互必须满足两个基本要求:同步和通信。进程同步本质上是一种仅能传送信号的进程通信,通过修改信号量,进程之间可以建立联系,相互协调和协同工作,但它缺乏传递数据的能力。在多任务环境中,可由多个进程分工协作完成同一任务,于是,它们需要共享一些数据和相互交换信息,某些情况下所交换的信息量很少, 但在大多场合需要交换大批数据,可以通过通信机制来完成,进程之间互相交换信息的工作成为进程通信(InterProcess Communication, IPC)。通信方式有很多,包括:
- 信号(signal)通信机制
- 管道(pipeline)通信机制
- 消息传递(message passing)通信机制
- 信号量(semaphore)通信机制
- 共享主存(shared memory)通信机制
其中,前两种是UNIX最早的版本就提供的进程通信机制,信号通信机制只能发送单个信号而不能传送数据;管道通信机制虽然能传送数据,却只能在进程家族内使用,应用范围有限。此后,UNIX System V版研制和开发后三种进程通信机制,这就是著名的System V IPC,其共性是,在同一机器上的任何进程都可以使用这些机制通信,且相互通信的进程并不需要有家族关系。而BSD UNIX则实现了套接字(socket)网络进程通信机制。
信号通信机制
信号(signal)是一种软中断,是传递短消息的简单通信机制,通过发送指定信号来通知进程某个异步事件发生,以迫使进程执行信号处理程序。信号处理完毕后,被中断进程将恢复执行。同中断和异常相比,多数信号对用户态进程是可见的,可以被应用进程捕获。信号可通过异常(硬中断)直接产生,如进程执行非法指令或段违例等,内核会发送给它SIGILL或SIGSEGV;进程也可发出信号,以实现进程的同步或终止,如SIGKILL将强迫另一进程终止。
信号本身不是字符串,也不是类似命令的结构,它们只是系统预先定义的整数值,而且这组定义是所有进程的共识。举例来说,如果在命令行启动的程序似乎“死”掉了,可能会选择按下Ctrl + C来中断该程序。事实上,按Ctrl + C这个动作其实是促使Shell帮你送出一个INT信号给正在占据终端机的进程。Linux系统定义了大约60余种信号。每种信号都具备两个属性:名称与数值,进程实际收到的是数值,名称只是方便理解而已。有许多信号是专供内核使用的,只有一部分信号可供一般用户使用。下表列举了一些可用交互方法传递的信号:
| 信号名称 | 数值 | 意义与应用 |
|---|---|---|
| SIGHUP | 1 | 挂断(hang up)。当你注销系统或中断调制解调器连接时,系统会自动发送此信号给所有活动中的进程。许多服务器进程收到此信号后,会重新读取自己的配置文件。因此,管理者常在修改了配置文件之后主动送出此信号给对应的服务器进程,使新配置生效 |
| SIGINT | 2 | 中断或停止运行。当键入Ctrl + C时,shell便会发送此信号到当前占据终端机的进程 |
| SIGKILL | 9 | 立即无条件结束运行。发出KILL信号是一种非常手段,任何进程都无法忽略此信号 |
| SIGTERM | 15 | 温和地(如果可能)终结进程。此信号用来要求进程以无伤害的方式逐步结束运行 |
| SIGTSTP | 20 | 暂停运行,待命恢复。当你键入Ctrl + Z时,进程收到的就是此信号 |
| SIGCONT | 18 | 恢复运行。此信号用来通知被TSTP或STOP暂停的进程,是它们恢复运行。在你用Ctrl + Z暂停一个进程之后,若下达了fg或bg命令,shell所送出的就是CONT信号 |
有些信号是借着人人都知道的按键组合Ctrl + C和Ctrl + Z来发送的。此外,还可以利用kill命令来发送任一信号。请注意,你的Linux系统上应有两个kill命令,一个是shell内置命令,另一个是独立存在的二进制命令。
kill
语法 kill [-s sigspec | –sigspec] [pids]
or kill -l [signum]
说明 第一种形式中的sigspec自变量代表你想发出的信号,它可以是数字形式的信号值,也可以是文字形式的信号名称,而且完整名称(例如SIGHUP)或简名(例如HUP)皆可。习惯上,信号名称都是以大写表示,但是kill也接受小写形式(不建议)。如果没指定sigspec,默认发送的信号是SIGTERM。pids自变量是接受信号的进程。
第二种形式的作用是列出有效的信号名称,如果指定了signum(一个整数),则只显示该数字对应的信号名称。
列出所有信号的名称与数值:$ kill -l
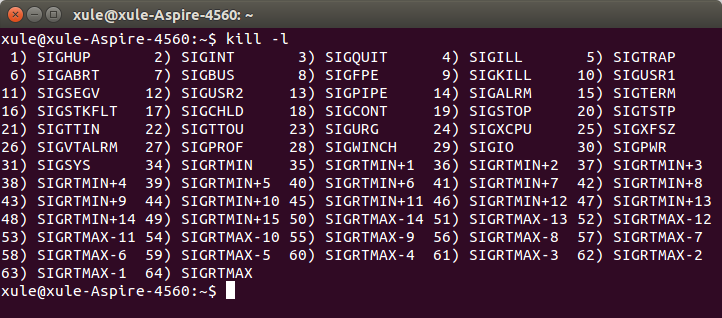
传送SIGTERM信号给PID 1000和1001两个进程(以下全是等效命令):
$ kill 1000 1001
$ kill -15 1000 1001
$ kill -SIGTERM 1000 1001
$ kill -sigterm 1000 1001
$ kill -TERM 1000 1001
$ kill -s 15 1000 1001
$ kill -s SIGTERM 1000 1001
假设PID 1000与1001这两个进程是依照POSIX标准规格写出来的正常程序,它们应该会遵守SIGTERM信号的指示,与准备妥当(即做完清理工作)后终止运行。然而,并非所有进程都会遵守信号的指示,对于早已陷入死胡同的进程,可能无法对这么温和的信号作出响应,也有些进程本身的设计会故意略过你所发送的信号。若要强制关闭这些进程:
$ kill -9 1000 1001
$ kill -KILL 1000 1001
上述两个等效命令同样都是送出无法略过的KILL信号给进程。不管当前是否还有未关闭的文件或其他的清理程序,收到此信号的进程都会立即终止运行。也就是说,KILL信号可能会造成数据遗失的后遗症,所以应视为最后不得已的非常手段,不过,你可能会遇到连KILL信号也无法终止的进程,此类问题多半与硬件有关,像是进程可能正在尝试将数据写入已失效的NFS服务器。
有superdaemon之称的inetd会在收到HUP信号之后重新读取自己的配置文件。如果你变更过该配置文件,而且想让inetd重新设定自己,请发送HUP信号给它:
$ kill -HUP `cat /var/run/inetd.pid`
终止进程
偶尔,你会发现系统反应迟钝,这时可先利用ps或top之类的进程监测工具进行调查。若发现某进程无缘无故用海量内存或是强占CPU不放,便可合理推论该进程是造成系统迟钝的原因。如果你知道问题进程的作用,确定该进程不是被外界植入的,你应该以温和渐进的手段来终结该进程,然后才进行软件升级或修改配置文件等釜底抽薪之道。另一方面,若你确定该进程根本不应该存在于系统上,则可以直接诉诸最后非常手段。举例来说,第一次该先送出TERM信号,如果没效果才送出KILL信号,再没有效果,你可能是遇到僵死进程(zombie)了,重新开机吧!
当你终结掉一个进程时,附属的所有子进程也会跟着消失。假如你终结掉的是一个shell,那么,任何从shell启动的进程也会跟着被终结掉。
Shell的工作控制
Linux是一种多用户多任务操作系统,shell对于“多任务”特性的具体呈现就在于它的作业控制机制。作业(job)是shell虚拟出来的概念,你在命令行下达的一个完整命令,无论该命令由几个工具构成,shell会将其视为一个“作业”。如果要比喻,shell环境下的一个“任务”就像图形环境中的一个“窗口”。如你所知,在窗口环境下,你可以同时开启好几个窗口,但只有一个窗口会接受你的操作(称为“活动窗口”或“前台窗口”),其余窗口在后台运作(称为“后台窗口”)。类似的情况,shell也可以人你启动多个作业,但是只有其中一个可占据控制台(console),称为“前台作业”(foreground job),其余不占控制台的则是“后台作业”(background job)。由于后台作业没有控制台的使用权,所以无法从键盘获得用户输入,也无法输出信息到屏幕,用户除了发送信号给它们之外,无法提供输入数据给它们。对于每一个后台作业,shell会自动赋予一个“作业编号”(由1起算,循序递增)。
后台作业不占据控制台的特性,主要是为了让用户可以运行需要长期运行的程序,而同时又保持终端机的可用性。举例来说,网站管理员经常需要运行日志分析程序,这类程序可将分析结果存储于文件而不需要用户交互操作,但是它们的运行时间相当长。在这种情况下,管理员可将分析工作放在后台运行,空出控制台来编辑网页或其他操作。
启动后台作业的方法是在整个命令的最后端补一个 & 符号,例如:
$ firefox &
[1] 1748
$
上述命令可启动Firefox浏览器,shell会显示出作业编号(在方括号内)与PID,随即让Firefox与控制台脱钩(unhook),让用户可以继续使用控制台。如果忘了附加&符号,你会发现shell不会显示出提示符号,而你自然也不能下达后续命令。对于这种情况,你可以先键入Ctrl + Z让程序暂停:
$ firefox
^Z
[1]+ Stopped firefox
然后执行bg命令将被暂停的程序放在后台,重新启动:
$ bg
[1]+ firefox &
$
同样的技巧也可以用于交互式程序。假设你现在正以ssh登录到远程的Linux系统并以文本模式来执行Emacs。突然间,你想到有件事必须要回到命令行处理,而你又不希望终止Emacs,于是你便按下了Ctrl + Z。Emacs会因此而被搁置于后台,将shell提示符号还给你。当你办完事之后,可用fg命令将Emacs拉回前台。
接下来是bg、fg和jobs这三个作业控制命令的摘要整理。你可以利用Ctrl + Z与bg命令将程序放到后台;利用fg命令将暂停的作业拉回前台运作;利用jobs来查看所有后台作业以及它们的状态。
bg
语法 bg [jobspec]
说明 此命令将指定的作业(jobspec)放到后台运行,就如同启动程序时附加了&符号。如果指定的jobspec不存在或是没指定任何作业,则shell会假定你是指当前的作业,也就是jobs所列作业列表中标示了加号(+)的那个作业。而被放在后台的作业会继续运作,不会停顿,除非运行到需要用户输入的阶段。
fg
语法 fg [jobspec]
说明 将控制台的使用权还给指定的作业(jobspec),也就是所谓的“拉回前台”,使其能与用户交互。如果jobspec不存在或是没指定任何作业。则shell会假定你是指当前作业。
jobs
语法 jobs [options] [jobspecs]
说明 列出当前所担负的所有未完作业或是jobspecs所指定的作业。
常用选项
-l 连同PID一起显示。
管道通信机制
管道(pipeline)是UNIX的传统进程通信方式,也是UNIX发展最有意义的贡献之一。它是连续读写进程的一个特殊文件,允许按照FCFS方式传送数据,也能使进程同步执行。管道是单向的,发送进程视管道文件为输出文件,以字符流的形式把大量数据送入管道;接收进程视管道为输入文件,从管道中接收数据,所以也称为管道通信。
当使用Shell命令:$ ps -ef | grep daemon 时,命令”ps -ef”是指列出当前系统中运行的所有进程,命令”grep daemon”是指从输入的字符串中查找包含字符”daemon”的子串,两个命令通过管道线”|”连接起来,其意义是指查找正在运行的、名字中包含”daemon”字符串的进程。两个命令在系统中运行之后,即为两个进程,管道就是连接这两个进程的通道。
管道的实质是一个共享文件,即利用辅助存储器来进行数据通信。因此,管道通信基本上可借助于文件系统的机制来实现,包括管道文件的创建、打开、关闭和读写。但是,写进程和读进程之间的相互协调单靠文件系统机制是解决不了的,读写进程相互同步,必须做到以下几点:
(1)进程正在使用管道写入或读取数据时,另一个进程必须等待。这一点是进程在读写管道之前,通过测试文件inode节点的特征位——读写互斥标志来保证的。若已锁住,进程便等待,否则,把inode上锁,然后,进行读写操作。操作结束后再行解锁并唤醒因节点上锁而等待的进程。
(2)发送者和接收者双方必须知道对方的存在。如果对方不存在,就没有必要再发送或接收信息,这时系统会发出SIGPIPE信号通知进程。
(3)发送信息和接收信息之间要实现正确的同步关系。这是由于管道文件只使用inode节点中的直接地址项,长度限于10个盘块,管道的长度限制对于进程的write和read操作会产生影响。如果进程执行一次写操作,且管道有足够的空间,那么,write操作会把数据写入管道后唤醒因此管道而等待的进程;如果此次操作会引起管道溢出,则本次write操作必须暂停,直到其他进程从管道中读取数据,使管道有空余空间为止,这叫做write阻塞。解决这个问题的办法是:把数据进行切分,每次均小于管道限制的字节数,写完后此进程睡眠,直到读进程把管道中的数据取走,并判别有进程等待时唤醒对方,以便继续写下一批数据。反之,当读进程读空管道时,要出现read阻塞,读进程应睡眠,直到写进程唤醒它。
管道又分为无名管道和有名管道,前者只能在父子进程之间通信中,而后者由于可以独立成磁盘文件存在,所以能够为无亲缘关系的进程提供通信服务。
一、无名管道
无名管道通常泛指为管道,在shell命令中使用的管道线就属于该类。它占用两个文件描述符,一般只应用于有亲缘关系的父子进程之间的通信上。管道由pipe函数在内核中创建,并分配两个文件描述符标识管道的两端,这两个文件描述符存储于fildes[0]和fildes[1]中。一般约定fildes[0]描述管道的输入端,进程向此文件描述符写数据,fildes[1]描述管道的输出端,进程从此文件描述符中读取数据。函数pipe原型如下:
#include <unistd.h>
int pipe(int fildes[2]);
若函数调用成功,返回0,否则返回-1。
例1:父进程生成p1、p2两个子进程,然后向管道写入各自数据,父进程负责读出这些数据。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
int main() {
int pid1, pid2, fd[2];
char buf[50], s[50];
pipe(fd);
pid1 = fork();
switch (pid1) {
case -1: perror("fork failed."); exit(1);
case 0: lockf(fd[1], 1, 0); // 锁定写入端
sprintf(buf, "child p1 is sending messages!\n");
write(fd[1], buf, 50);
sleep(5);
lockf(fd[1], 0, 0); // 释放写入端
exit(0);
default: pid2 = fork();
switch (pid2) {
case -1: perror("fork failed."); exit(1);
case 0: lockf(fd[1], 1, 0); // 锁定写入端
sprintf(buf, "child p2 is sending messages!\n");
write(fd[1], buf, 50);
sleep(5);
lockf(fd[1], 0, 0);
exit(0);
default: wait(NULL);
read(fd[0], s, 50);
printf("%s", s);
wait(NULL);
read(fd[0], s, 50);
printf("%s", s);
exit(0);
}
}
close(fd[0]);
close(fd[1]);
return 0;
}
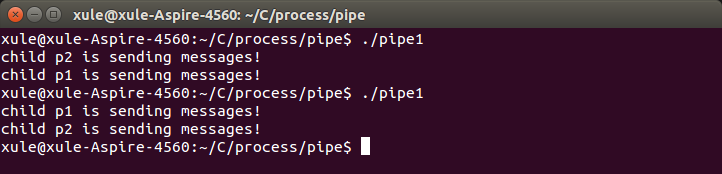
试想,若pipe调用放在fork之后,结果会怎样呢?显然,结果会不一样。这主要是因为pipe放在fork之后,使得子进程无法复制父进程有关管道的创建,这样子进程也无法使用该管道,从而无法达到设计要求。
此外,还有一组内含管道的函数比较常见,其函数原型如下:
#include <stdio.h>
FIFE *popen(const char *command, char *type);
int pclose(FILE *stream);
函数popen首先fork一个子进程,然后调用exec执行command中给定的命令,并且自动在父进程与子进程之间建立管道,用于连接子进程的标准输入、输出,参数type指定了管道的I/O类型,请函数语法说明如下表:
| 所需头文件 | #include <stdio.h> | ||
|---|---|---|---|
| 函数原型 | FILE *popen(const char *command, char *type); | ||
| 参数 | command | 指定新程序 | |
| type | r | 创建与子进程的标准输出连接的管道(管道数据由子进程流向父进程) | |
| w | 创建与子进程的标准输入连接的管道(管道数据由父进程流向子进程) | ||
| 返回值 | 若调用成功,返回一个标准I/O的FILE文件流,否则返回NULL | ||
函数pclose用于关闭由popen打开的文件流,若调用成功,则返回exec进程退出时的状态,否则返回-1。
例2:设计一个模拟命令”ps -ef |grep daemon”的程序。
#include <stdio.h>
int main() {
FILE *out, *in;
char buf[255];
if ((out = popen("grep daemon", "w")) == NULL) {
fprintf(stderr, "error!\n");
return 1;
}
if ((in = popen("ps -ef", "r")) == NULL) {
fprintf(stderr, "error!\n");
return 1;
}
while (fgets(buf, sizeof(buf), in))
fputs(buf, out);
pclose(out);
pclose(in);
return 0;
}
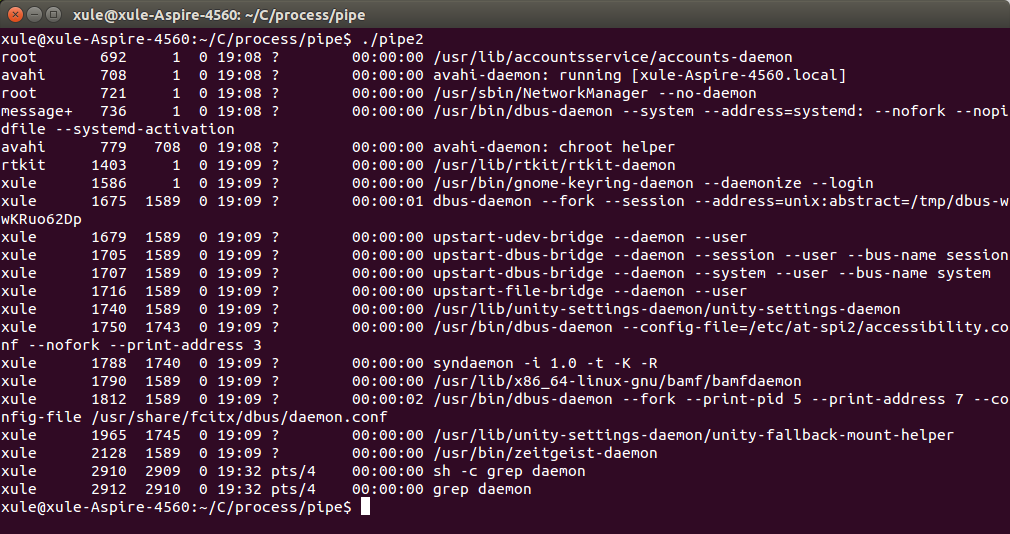
下面对基于无名管道的进程间通信进行小结:
- 无名管道只能用于具有亲缘关系的进程自己的的通信(也就是父子进程或者兄弟进程之间);
- 无名管道是一个半双工的通信模式,具有固定的读端和写端;
- 无名管道可以看成是一种特殊的文件,对于它的读写也可以使用普通的read和write等函数,但是它不是普通的文件,并不属于其他任何文件系统,并且只能存在于内核的内存空间中。
二、有名管道FIFO
由于无名管道只能用于具有亲缘关系的进程之间,进而大大限制了管道的应用范围。若需要互相通信的两个进程没有亲缘关系、无法从公共祖先那里继承文件描述符时,它们将如何通信呢?内核提供一条通道是不成问题的,问题是如何标识这条通道才能使各进程都可以访问它。由于文件系统中的路径名是全局的,各进程都可以访问,所以使用文件系统中的路径名来标识一个进程间通信的通道在理论上是完全可行的,而这一通道正是所谓的有名管道。
为了实现有名管道,UNIX中引人了一种新的文件类型——FIFO文件(遵循先进先出的原则)。实现一个有名管道实际上就是实现一个FIFO文件。有名管道一旦建立,对它的读、写以及关闭操作都与普通文件完全相同,但FIFO并非普通文件,除i节点在磁盘上以外,其文件的数据部分均存储于内核缓冲区中。此外,FIFO是严格地遵循先进先出规则的,对管道及FIFO的读总是从开始处返回数据,对管道的写则把数据添加到末尾,它们不支持如lseek()等文件定位操作。
(1)FIFO的创建
有名管道的创建可以使用mkfifo(或者在终端中调用mkfifo命令创建),该函数类似文件中的open()操作,可以指定管道的路径和打开的模式。其函数语法要点如下表所示:
| 所需头文件 | #include <sys/types.h>
#include <sys/stat.h> |
|
|---|---|---|
| 函数原型 | int mkfifo(char *path, mode_t mode); | |
| 参数 | path | 指定管道的路径 |
| mode | O_RDONLY: 读管道 | |
| O_WRONLY: 写管道 | ||
| O_RDWR: 读写管道 | ||
| O_NONBLOCK: 非阻塞 | ||
| O_CREAT: 如果该文件不存在,那么就创建一个新的文件,并用第三个参数为其设置权限 | ||
| O_EXCL: 如果使用O_CREAT时文件存在,那么可返回错误消息。这一参数可测试文件是否存在 | ||
| 函数返回值 | 若调用成功,返回0,否则返回-1 | |
(2)FIFO的删除
类似于删除文件,unlink(char *path)函数可以用来删除FIFO。
(3)对FIFO连接的监听
使用open(path, O_RDONLY)函数。open函数阻塞进程直到某个进程打开FIFO进行写操作。
(4)FIFO会话
使用open(path, O_WRONLY)函数。open函数阻塞进程直到某个进程打开FIFO进行读取操作。
(5)通过FIFO实现两进程通信
发送进程用write调用,监听进程使用read调用。最后写进程调用close来通知读进程通信结束。
例3:设计两个程序:一个用于读管道,另一个用于写管道,其中在写管道的程序里创建管道,并且作为main函数里的参数由用户输入要写入的内容。读管道的程序会读出用户写入到管道的内容,这两个程序采用的是阻塞式读写管道模式。
写管道程序:
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <fcntl.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#define MYFIFO "./myfifo" // 有名管道文件名
#define MAX_BUFFER_SIZE PIPE_BUF // 定义在limits.h中
int main(int argc, char *argv[]) {
int fd;
char buff[MAX_BUFFER_SIZE];
int nwrite;
if (argc <= 1) {
printf("Usage: ./fifo_write string\n");
exit(1);
}
sscanf(argv[1], "%s", buff);
// 以只写阻塞方式打开FIFO管道
fd = open(MYFIFO, O_WRONLY);
if (fd == -1) {
printf("Open fifo file error\n");
exit(1);
}
// 向管道中写入字符串
if ((nwrite = write(fd, buff, MAX_BUFFER_SIZE)) > 0) {
printf("Write '%s' to FIFO\n", buff);
}
close(fd);
exit(0);
}
读管道程序:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <limits.h>
#include <fcntl.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#define MYFIFO "./myfifo" // 有名管道文件名
#define MAX_BUFFER_SIZE PIPE_BUF // 定义在limits.h中
int main() {
char buff[MAX_BUFFER_SIZE];
int fd;
int nread;
// 判断有名管道是否已经存在,若尚未创建,则以相应的权限创建
if (access(MYFIFO, F_OK) == -1) {
if ((mkfifo(MYFIFO, 0666) < 0) && (errno != EEXIST)) {
printf("Cannot create fifo file\n");
exit(1);
}
}
fd = open(MYFIFO, O_RDONLY);
if (fd == -1) {
printf("Open fifo file error\n");
exit(1);
}
while (1) {
memset(buff, 0, sizeof(buff));
if ((nread = read(fd, buff, MAX_BUFFER_SIZE)) > 0)
printf("Read '%s' from FIFO\n", buff);
}
close(fd);
exit(0);
}

下面对基于有名管道的进程间通信进行小结:
- 进程打开有名管道时需要确认管道对端进程的存在,否则该进程将阻塞。也就是说,若有进程打开有名管道进行读操作,则必须在有名管道的另一端有写操作进程存在,否则读进程将阻塞,直到对端有写进程出现为止;
- 虽然操作有名管道如图普通操作文件,但是它与普通文件有着本质的区别,即有名管道不使用磁盘的数据区存放数据而是使用内核缓冲区存放数据;
- 与无名管道相同,在使用有名管道读数据时也会将数据从管道中移去,所以有名管道也不能用来对多个接收者广播数据;
- 有名管道中的数据被当做字节流,因此无法识别信息的边界;
- 若一个有名管道有多个读进程,那么写进程不能发送数据到指定的读进程。同样,若有多个写进程,则无法判断哪一个是发送数据的进程。
消息传递通信机制
交互式并发进程通过信号量和P、V操作可实现进程的同步互斥。当进程之间需要交换更多的信息时,需要引入高级通信方式————消息传递(message passing)机制(UNIX和Linux中称其为消息队列)来实现。由于操作系统所提供的这类机制隐蔽实现细节,通过消息传递机制完成通信,就能简化程序编制的复杂性,方便易用。
消息传递的复杂性在于:地址空间的隔离,发送进程无法将消息直接复制到接收进程的地址空间中,这项工作仅能由操作系统来完成。为此,消息传递机制至少需要提供两条原语send和receive,前者向一个给定的目标进程发送一条消息,后者则从一个给定的源进程接收一条消息。如果没有消息可用,则接收者可能阻塞直至一条消息到达,或者也可立即返回,并带回一个错误码。采用消息传递机制后,进程之间用消息来交换信息,一个运行进程可在任意时刻向另一个运行进程发送一条消息;一个运行进程也可在任何时刻向另一个运行进程请求一条消息。
在UNIX中,消息队列是内核中的一个先进先出的队列型链表结构。在许多方面看来,消息队列类似于有名管道,也有对最大数据块的限制,也存在使用有名管道时所遇到的阻塞问题,但是消息队列能够独立于发送与接收过程,这使得它没有诸如打开与关闭管道时所出现的复杂关联,从而可以有效避免同步问题。多个进程可以同时向一个消息队列写消息,也可以同时从一个消息队列中读取消息。写进程把消息写到队列的尾部,读进程从消息队列的头部读取消息,消息一旦被读出将会从队列中删除。
(1)对消息队列的管理和表示
UNIX内核采用结构msqid_ds来管理消息队列,其数据成员可与命令”ipcs -a -q”中显示结果对应。其数据结构定义如下:
struct msqid_ds {
struct ipc_perm msg_perm; // 消息队列的访问权限
struct msg *msg_first; // 队列中指向第一个消息的指针
struct msg *msg_last; // 队列中指向最后一个消息的指针
__kernel_time_t msg_stime; // 最后发送消息的时间
__kernel_time_t msg_rtime; // 最后接收消息的时间
__kernel_time_t msg_ctime; // 最后修改时间
struct wait_queue *wwait; // 等待向消息队列写的进程指针
struct wait_queue *rwait; // 等待从消息队列读的进程指针
unsigned short msg_cbytes; // 队列中当前字节数
unsigned short msg_qnum; // 队列中的消息数
unsigned short msg_qbytes; // 队列中的最大字节数
__kernel_ipc_pid_t msg_lspid; // 最后一次向消息队列写入消息的进程ID
__kernel_ipc_pid_t msg_lrpid; // 最后一次从消息队列读取消息的进程ID
}
消息队列中的各个消息都存储在结构为msg结构的空间中,它们是消息队列的主要组成部分,其数据结构定义如下:
struct msg {
struct msg *msgnext; // 指向消息队列中下一个消息
long msg_type; // 本条消息的类型
short msg_ts; // 本条消息的长度
short msg_spot; // 本条消息的数据地址
}
理论上用户可以通过结构msgid_ds成员中的msg_first和msg_last指针与结构msg成员中的msg_next指针遍历所有消息队列,并能完成管理和维护队列等任务,但在实际上这3个成员均属于UNIX内核的直辖数据,用户无权引用。消息队列的结构如下图所示:
此处留截图。
由于消息结构中只有消息类型和消息数据是用户定义的,所以UNIX提供了一个消息模板msgbuf,也称消息缓冲,为用户编程使用。其结构定义如下:
struct msgbuf {
long mtype; // 消息类型
int ntext; // 消息数据
}
其中mtype指定了消息类型,其取值为正整数。消息类型的引入,可以更大程度上复用消息队列。可以根据不同功能的信息,定义不同的消息类型,从而共享一个消息队列。ntext指定了消息的数据,这里用整型来定义其数据类型,但事实上它可以是任意的数据类型甚至包括结构。
(2)对消息队列的操作
通常使用这些函数,其原型如下:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgget(key_t key, int msgflg);
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
int msgrcv(int msqid, void *msgp, size_t msgsz, long msgtype, int msgflg);
其中,函数msgget为创建或打开消息队列,函数msgsnd为向消息队列发送消息,函数msgrcv为从消息队列中接收消息。其函数语法要点分别如下列表格:
表:msgget函数语法要点
| 所需头文件 | #include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> |
||
|---|---|---|---|
| 函数原型 | int msgget(key_t key, int msgflg); | ||
| 参数 | key | 消息队列关键字 | |
| msgflg | 低9位指定队列的属主、属组和其他用户的访问权限 | ||
| IPC_CREAT | 创建消息队列,如果队列已经存在,就打开消息队列 | ||
| IPC_EXCL | 与宏IPC_CREAT一起使用,单独使用无意义。创建一个不存在的消息队列,如果队列已经存在,函数调用失败 | ||
| 函数返回值 | 若函数调用成功,返回消息队列标识符,否则返回-1 | ||
表:msgsnd函数语法要点
| 所需头文件 | #include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> |
||
|---|---|---|---|
| 函数原型 | int msgsnd(int msgid, const void *msgp, size_t msgsz, int msgflg); | ||
| 参数 | msgid | 指定发送消息队列的标识号 | |
| msgp | 指向存储待发送消息内容的内存地址,其数据结构类似于结构msgbuf | ||
| msgsz | 指定发送消息数据的长度,仅记载消息数据的长度,不包括消息类型部分且取值大于0 | ||
| msgflg | 无设置 | 阻塞方式发送 | |
| IPC_NOWAIT | 非阻塞方式发送 | ||
| 函数返回值 | 若消息发送成功,则返回0,否则:
|
||
表:msgrcv函数语法要点
| 所需头文件 | #include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> |
|
|---|---|---|
| 函数原型 | int msgrcv(int msgid, void *msgp, size_t msgsz, long msgtype, int msgflg); | |
| 参数 | msgid | 指定发送消息队列的标识号 |
| msgp | 指向存储待发送消息内容的内存地址,其数据结构类似于结构msgbuf | |
| msgsz | 指定发送消息数据的长度,仅记载消息数据的长度,不包括消息类型部分且取值大于0 | |
| msgtype | 0:读取消息队列中第一个类型为msgtype的消息(队列头消息) | |
| 正整数:读取消息队列中第一个类型为msgtype的消息(最接近队列头的消息) | ||
| 负整数:读取消息队列中第一个类型小于或等于msgtype的绝对值的消息 | ||
| msgflg | 无设置:阻塞方式读取消息 | |
| IPC_NOWAIT:非阻塞方式读取消息 | ||
| MSG_NOERROR:截断读取消息 | ||
| 函数返回值 | 若函数调用成功,则返回实际接收消息数据的长度,否则:
|
|
例4:设计两个程序,通过消息队列传递字符串信息,其中发送程序可以循环读取键盘输入,并将字符串信息发送到标识为0x1000的消息队列中;接收程序能够以阻塞方式从标识为0x1000的消息队列中接收消息。
发送程序:
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/errno.h>
extern int errno;
struct mymsgbuf {
long mtype;
char ctext[100];
};
int main(void)
{
struct mymsgbuf buf;
int msid;
if ((msid = msgget(0x1000, 0666 | IPC_CREAT)) < 0 ) {
fprintf(stderr, "open msg %X failed.\n", 0x1000);
return 1;
}
while (strncmp(buf.ctext, "exit", 4)) {
memset(&buf, 0, sizeof(buf));
fprintf(stderr, "Please input: ");
fgets(buf.ctext, sizeof(buf.ctext), stdin);
buf.mtype = 100;
while ((msgsnd(msid, &buf, strlen(buf.ctext), 0)) < 0) {
if (errno == EINTR) continue;
return 1;
}
}
return 0;
}
接收程序:
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/errno.h>
extern int errno;
struct mymsgbuf {
long mtype;
char ctext[100];
};
int main(void)
{
struct mymsgbuf buf;
int msid;
int ret;
if ((msid = msgget(0x1000, 0666 | IPC_CREAT)) < 0) {
fprintf(stderr, "open msg %X failed.\n", 0x1234);
return 1;
}
while (strncmp(buf.ctext, "exit", 4)) {
memset(&buf, 0, sizeof(buf));
while ((ret = msgrcv(msid, &buf, sizeof(buf.ctext), 0, 0)) < 0) {
if (errno == EINTR) continue;
return 1;
}
fprintf(stderr, "Msg : Type=%ld, Len=%d, Text=%s", buf.mtype, ret, buf.ctext);
}
return 0;
}
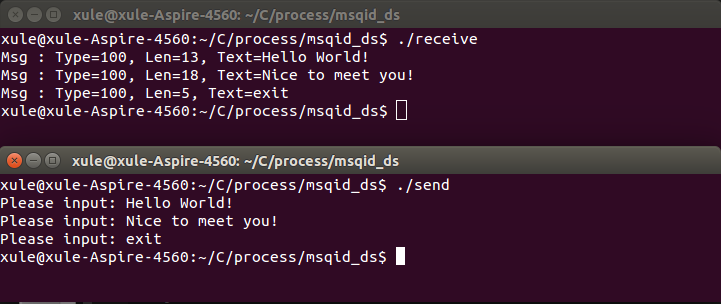
(3)对消息队列的控制
对消息队列的控制函数msgctl,可以通过它对消息队列执行各种控制,其中包括查询消息队列数据结构、改变消息队列访问权限、改变消息队列属主信息和删除消息队列等。其函数语法要点如下表所示:
| 所需头文件 | #include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> |
||
|---|---|---|---|
| 函数原型 | int msgctl(int msgid, int cmd, struct msqid_ds *buf); | ||
| 参数 | msgid | 指定发送消息队列的标识号 | |
| cmd | IPC_RMID | 删除消息队列msgid及其相关联的数据结构,此时消息队列中未被及时读取的消息数据将丢失 | |
| IPC_STAT | 读取消息队列数据结构msgid_ds,并存储到缓冲区buf中 | ||
| IPC_SET | 设置消息队列结构msgid_ds的成员msg_perm.uid、msg_perm.gid、msg_perm.mode(仅仅低9位)和msg_qbytes,分别改变消息队列的有效用户ID、组ID、访问权限和消息队列字节数的信息,这些值由参数buf传入 | ||
| buf | 消息队列缓冲区 | ||
| 函数返回值 | 若函数调用成功,返回0,否则返回-1 | ||
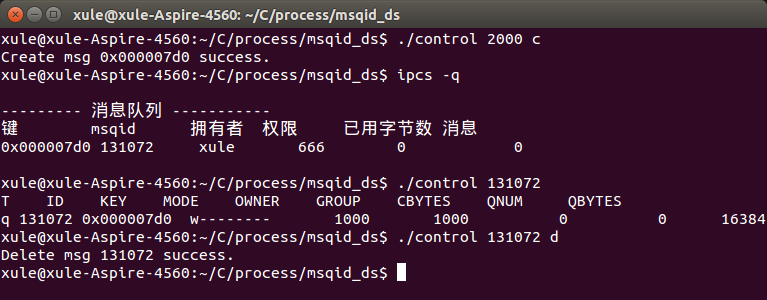
例5:从命令行参数中获取要执行的操作,包括创建消息队列、读取消息队列和删除消息队列等,类似于命令”ipcs”的程序。
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/stat.h>
char *getFileMode(mode_t st_mode, char *resp) {
memset(resp, '-', 9);
if (st_mode & S_IRUSR) resp[0] = 'r';
if (st_mode & S_IWUSR) resp[0] = 'w';
if (st_mode & S_IXUSR) resp[0] = 'x';
if (st_mode & S_IRGRP) resp[0] = 'r';
if (st_mode & S_IWGRP) resp[0] = 'w';
if (st_mode & S_IXGRP) resp[0] = 'x';
if (st_mode & S_IROTH) resp[0] = 'r';
if (st_mode & S_IWOTH) resp[0] = 'w';
if (st_mode & S_IXOTH) resp[0] = 'x';
resp[9] = 0;
return resp;
}
int statMsg(int msgid) {
char resp[20];
struct msqid_ds buf; // 申请消息队列结构缓冲区
memset(&buf, 0, sizeof(buf)); // 置空消息队列结构缓冲区
msgctl(msgid, IPC_STAT, &buf); // 读取消息队列结构
// 转化消息队列结构并打印
fprintf(stderr, "T ID KEY MODE OWNER GROUP CBYTES QNUM QBYTES\n");
fprintf(stderr, "q %6d %#10.8x %10s %10d %10d %10d %10d %10d\n", msgid, buf.msg_perm.__key, getFileMode(buf.msg_perm.mode, resp), (int)buf.msg_perm.uid, (int)buf.msg_perm.gid, (int)buf.msg_cbytes, (int)buf.msg_qnum, (int)buf.msg_qbytes);
}
int main(int argc, char *argv[]) {
int msgid;
if (argc != 2 && argc != 3)
return 0;
msgid = atoi(argv[1]);
if (argc == 2) {
statMsg(msgid);
}
else if (argc == 3 && strcmp(argv[2], "c") == 0) {
// 创建消息队列
if (msgget(msgid, 0666 | IPC_CREAT | IPC_EXCL) < 0)
fprintf(stderr, "Create msg %#10.8x failed.\n", msgid);
else
fprintf(stderr, "Create msg %#10.8x success.\n", msgid);
}
else if (argc == 3 && strcmp(argv[2], "d") == 0) {
// 删除消息队列
if (msgctl(msgid, IPC_RMID, NULL) < 0)
fprintf(stderr, "Delete msg %d failed.\n", msgid);
else
fprintf(stderr, "Delete msg %d success.\n", msgid);
}
return 0;
}
下面对基于消息队列的进程间通信进行小结:
- 消息队列和管道提供相似的服务,但消息队列克服了管道所存在的问题,并在某些方面表现突出。比如由于消息队列传递的消息是不连续的、有格式的信息,因而在应用中带来较大的灵活性;再比如利用类型域,可以对消息作不同的解释(优先级、指定接收者等),使得传递的信息内容更加丰富。
- 小消息的传送效率很高,但大消息的传送性能则较差。因为消息传送的过程中要经过从用户空间到系统空间,再从系统空间到用户空间的复制,所以,对于大消息的传送性能较差。另外,消息队列不支持广播,而且内核不知道消息的接收者。
共享主存通信机制
共享主存是指在主存中开辟一个公共存储区,要通信的进程把自己的虚地址空间映射到共享主存区。当发送进程将信息写入共享主存区的某个位置时,接收进程可从此位置读取信息,由于共享主存区同时出现在进程A和进程B的虚存空间中,从而能实现进程之间的通信。由于不必在用户空间和系统空间之间进行数据复制,该机制是进程通信中最快捷和最有效的方法,此机制最早是在UNIX System V中作为进程通信的一部分而设计的。通过共享主存API,允许进程动态地定义共享主存区,由于进程的虚存地址空间相当大,所定义的共享主存区应对应一段未使用的虚地址区,以免与进程映像区发生冲突。共享主存的页面在每个共享进程的页表中都有页表项引用,但无须在所有进程的虚存段都有相同的地址。因为不止一个进程可将共享主存映射到自己的虚地址空间中去,读写共享主存区的代码段通常被认为是临界区。
(1)对共享内存的管理和表示
共享内存本质上就是一段物理内存,是一段由多个进程共享访问的区域。它被进程映射之后即作为普通内存使用,而不必使用额外的read和write系统调用。共享内存中的数据一旦被更改,其他映射到该内存的进程便会立刻体现,所以多个进程对同一共享内存的访问必须提供同步机制,但是共享内存不同于共享文件,无法提供锁机制,为此,用户进程必须自己完成相关操作。一般情况下共享内存常与信号量机制共同使用,由信号量完成对共享内存的锁操作。
UNIX内核采用结构shmid_ds来管理共享内存,其数据成员可用命令”ipcs -a -m”显示。其结构定义如下:
struct shmid_ds {
srtuct ipc_perm shm_perm; // 共享内存的访问权限
int shm_segsz; // 以字节为单位的共享内存大小
__kernel_time_t shm_atime; // 最近一次映射共享内存的时间
__kernel_time_t shm_dtime; // 最近一次取消共享内存映射的时间
__kernel_time_t shm_ctime; // 最近修改共享内存的时间
__kernel_ipc_pid_t shm_cpid; // 创建共享内存的用户ID
__kernel_ipc_pid_t shm_lpid; // 最近一次操作共享内存的用户ID
unsigned short shm_nattch; // 当前链接数,仅供shminfo使用
unsigned short shm_cnattch; // 核心链接数,仅供shminfo使用
};
(2)共享内存的使用
进程使用共享内存,一般的做法是:首先调用函数shmget创建或获取共享内存标识号,然后调用函数shmat将该共享内存段映射到进程地址空间中,之后无须更多的系统调用,进程可以像访问普通内存空间一样访问该共享内存,若使用完毕,需调用shmdt函数释放映射。由上可知,对共享内存的操作没有read或write之类的读写调用函数,而是映射函数和取消映射函数。
对共享内存的操作,通常使用这样一些函数,其函数原型如下:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
void *shmat(int shmid, const void *shmaddr, int shmflg);
int shmdt(const void *shmaddr);
其中, shmget函数用来创建或获取共享内存,函数shmat可以将共享内存映射到进程地址空间,函数shmdt用来释放共享内存映射,其函数语法要点如下列表格所示:
表:函数shmget语法要点
| 所需头文件 | #include <sys/types.h> #include <sys/ipc.h> #include <sys/shm.h> |
||
|---|---|---|---|
| 函数原型 | int shmget(key_t key, size_t size, int shmflg); | ||
| 参数 | key | 共享内存关键字 | |
| size | 共享内存的字节大小 | ||
| shmflg | 低9位指定共享内存的属主、属组和其他用户的访问权限 | ||
| IPC_CREAT | 创建共享内存,如果共享内存已经存在,就获取该共享内存的标识号 | ||
| IPC_EXCL | 与宏IPC_CREAT一起使用,单独使用无意义。创建一个不存在的共享内存,如果共享内存已经存在,函数调用失败 | ||
| 返回值 | 若函数调用成功,返回共享内存标识号,否则返回-1 | ||
表:函数shmat语法要点
| 所需头文件 | #include <sys/types.h> #include <sys/ipc.h> #include <sys/shm.h> |
||
|---|---|---|---|
| 函数原型 | void *shmat(int shmid, const void *shmaddr, int shmflg); | ||
| 参数 | shmid | 要映射的共享内存标识号 | |
| shmaddr | 共享内存的起始地址,若为NULL,则映射地址由系统自动选择 | ||
| shmflg | 未置SHM_RND | 则映射地址为shmaddr(shmaddr为非NULL) | |
| SHM_RND | 则映射地址为shmaddr – (shmaddr % SHMLBA) | ||
| 常数SHMBLA代表低边界地址的倍数 | |||
| 函数返回值 | 若函数调用成功,返回共享内存映射空间的起始地址,否则返回-1 | ||
表:函数shmdt语法要点
| 所需头文件 | #include <sys/types.h> #include <sys/ipc.h> #include <sys/shm.h> |
|---|---|
| 函数原型 | int shmdt(const void *shmaddr); |
| 参数 | shmaddr:共享内存的起始地址 |
| 函数返回值 | 若函数调用成功,返回0,否则返回-1 |
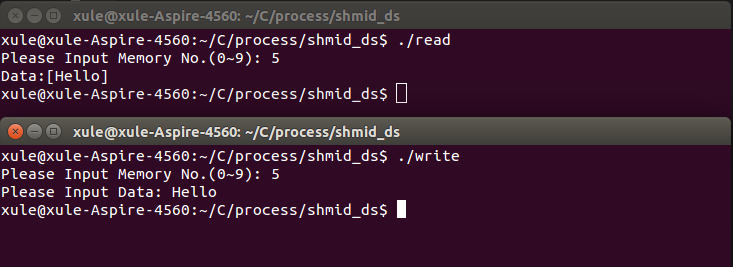
例6:设计两个程序共享一个内存段,程序A向共享内存段写入数据,程序B从共享内存段读出数据并显示。
程序A:
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int main(void)
{
int shmid;
char *pmat = NULL;
char buf[1024];
int no;
if ((shmid = shmget(0x5678, 10*1024, 0666 | IPC_CREAT)) == -1)
fprintf(stderr, "shmget failed.\n");
if ((pmat = (char *)shmat(shmid, 0, 0)) == 0)
fprintf(stderr, "shmat failed.\n");
printf("Please Input Memory No.(0~9): ");
scanf("%d", &no);
if (no < 0 || no > 9)
fprintf(stderr, "Select Memory block failed.\n");
printf("Please Input Data: ");
memset(buf, 0, sizeof(buf));
scanf("%s", buf);
memcpy(pmat + no*1024, buf, 1024);
shmdt(pmat);
return 0;
}
程序B:
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int main(void)
{
int shmid;
char *pmat = NULL;
char buf[1024];
int no;
if ((shmid = shmget(0x5678, 10*1024, 0666 | IPC_CREAT)) == -1)
fprintf(stderr, "shmget failed.\n");
if ((pmat = (char *)shmat(shmid, 0, 0)) == 0)
fprintf(stderr, "shmat failed.\n");
printf("Please Input Memory No.(0~9): ");
scanf("%d", &no);
if (no < 0 || no > 9)
fprintf(stderr, "Select Memory block failed.\n");
memcpy(buf, pmat + no*1024, 1024);
printf("Data:[%s]\n", buf);
shmdt(pmat);
return 0;
}
(3)对共享内存的控制
与消息队列一样,共享内存也有自己的控制函数shmctl,其函数语法要点如下表所示:
| 所需头文件 | #include <sys/types.h> #include <sys/ipc.h> #include <sys/shm.h> |
||
|---|---|---|---|
| 函数原型 | int shmctl(int shmid, int cmd, struct shmid_ds *buf); | ||
| 参数 | shmid | 共享内存标识号 | |
| buf | 为函数提供输入输出数据 | ||
| cmd | IPC_STAT | 读取共享内存信息 | |
| IPC_SET | 设置共享内存信息 | ||
| IPC_RMID | 删除共享内存,buf忽略 | ||
| SHM_LOCK | 锁定共享内存,buf忽略 | ||
| SHM_UNLOCK | 解锁共享内存,buf忽略 | ||
| 函数返回值 | 若函数调用成功,返回0,否则返回-1 | ||
例7:从命令行参数中获取要执行的操作,包括创建共享内存、读取共享内存和删除共享内存,类似于命令”ipcs”的程序。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/shm.h>
#include <sys/ipc.h>
#include <sys/stat.h>
char *getFileMode(mode_t st_mode, char *resp) {
memset(resp, '-', 9);
if (st_mode & S_IRUSR) resp[0] = 'r';
if (st_mode & S_IWUSR) resp[0] = 'w';
if (st_mode & S_IXUSR) resp[0] = 'x';
if (st_mode & S_IRGRP) resp[0] = 'r';
if (st_mode & S_IWGRP) resp[0] = 'w';
if (st_mode & S_IXGRP) resp[0] = 'x';
if (st_mode & S_IROTH) resp[0] = 'r';
if (st_mode & S_IWOTH) resp[0] = 'w';
if (st_mode & S_IXOTH) resp[0] = 'x';
resp[9] = 0;
return resp;
}
void statShm(int shmid) {
char resp[20];
struct shmid_ds buf;
memset(&buf, 0, sizeof(buf));
shmctl(shmid, IPC_STAT, &buf);
fprintf(stderr, "T ID KEY MODE OWNER GROUP NATTCH SEGSZ CPID LPID\n");
fprintf(stderr, "m %6d %10s %10d %10d %10d %10d %10d %10d\n", shmid, getFileMode(buf.shm_perm.mode, resp), buf.shm_perm.uid, buf.shm_perm.gid, buf.shm_nattch, (int)buf.shm_segsz, (int)buf.shm_cpid, (int)buf.shm_lpid);
}
int main(int argc, char *argv[]) {
int shmid, size;
if (argc != 3) return 0;
shmid = atoi(argv[1]);
if (strcmp(argv[2], "v") == 0)
statShm(shmid);
else if (strcmp(argv[2], "d") == 0) {
if (shmctl(shmid, IPC_RMID, NULL) < 0) {
fprintf(stderr, "shmctl failed.\n");
return 1;
}
printf("Delete Shm successs.\n");
}
else {
size = atoi(argv[2]);
if (shmget(shmid, size, 0666 | IPC_CREAT | IPC_EXCL) < 0) {
fprintf(stderr, "shmget failed.\n");
return 1;
}
printf("Create Shm success.\n");
}
return 0;
}
运行结果说明:
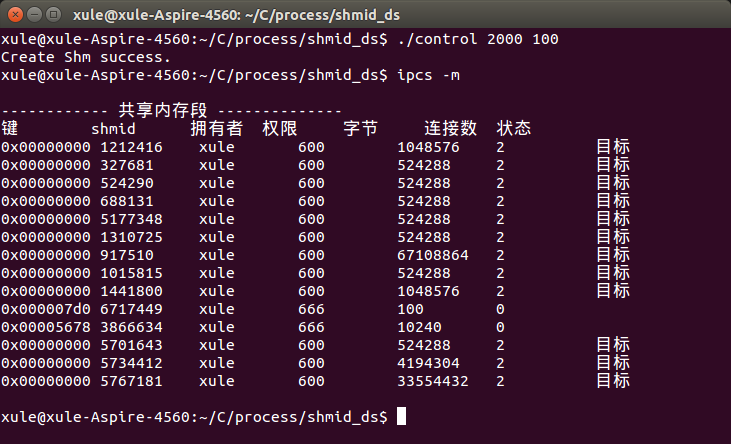
①. 创建关键字为2000,大小为100B的共享内存,并通过”ipcs -m”命令查询,其中标识号为()的共享内存便是新创建的,如下图所示:
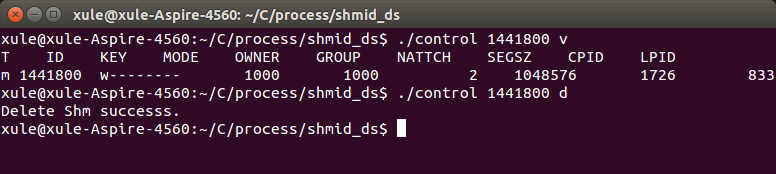
②. 调用本程序查询共享内存信息,并将其删除,如下图所示:
下面对基于共享内存的进程间通信进行小结:
共享内存提供了一种快速灵活的机制,它允许进程之间直接共享大量的数据,而无须使用副本或系统调用。
共享内存的主要局限性是它不能提供同步,如果两个进程企图修改相同的共享内存区域,由于内核不能将这些动作串行化,因此写的数据可能任意地互相混合,所以使用共享内存的进程必须设计它们之间的同步机制。
通过文件的通信机制
进程间还可以通过文件来进行通信。当某个进程将数据写入文件时,其他进程再将数据从文件中读出。
例8:一进程每隔10s向一个文件写当前的时间,另一进程从该文件中读取信息,这里以shell脚本来完成此任务。
写文件进程:
#!/bin/sh
# time.sh
while true; do
date >> /tmp/my_date
sleep 10
done
读文件进程可以使用命令:$ cat /tmp/my_date
写文件进程每隔10秒通过追加重定向符”>>”将当前时间和日期写入文件my_date,而在另一终端开启一进程查看该文件my_date。如此,两个进程通过一个文件实现了它们之间的通信。
其实进程之间进行网络通信所使用的套接字socket也是一种文件,基于套接字的通信实际上就是基于文件的主机之间的进程通信。
下面对基于文件的进程间通信进行小结:
- 参与通信的每个进程至少对该文件拥有读或写的权限;
- UNIX不限制同时打开同一文件的进程数目;
- 进程之间存在竞争条件,无论是“先读后写”、“先写后读”还是“先写后写”都需要使用互斥量或文件锁等相关的同步机制;
- 假设进程1将信息写入文件,进程2从文件中读取信息,在阻塞方式下,若进程1一直在写文件,则进程2中的read调用将被挂起,直到进程1结束写操作write为止。所以在此情况下若要实现两进程间的相互收发信息,则必须要使两进程不断地切换读、写角色才能正常工作。而在非阻塞方式下,两进程不需要做角色切换也能正常工作,但是该工作方式将占用更多的CPU时间,系统开销较大。所以在使用文件进行进程间通信时,应注意选择适合的应用领域。