参考文献:《算法导论(中文第二版)》Thomas H.Cormen, Charles E.Leiserson, Ronald L.Rivest, Clifford Stein [著]、《数据结构(C语言版)》严蔚敏, 吴伟民 [著]
在二叉查找树(binary search tree)上执行基本操作的时间与树的高度成正比,对于一棵含 n 个结点的完全二叉树,这些操作的最坏情况运行时间为 Θ(log n)。二叉查找树中关键字的存储方式总是满足以下性质:设 x 为二叉查找树中的一个结点,若 y 是 x 的左子树中的一个结点,则 key[y] <= key[x],若 y 是 x 的右子树中的一个结点,则 key[y] >= key[x]。
二叉查找树的结点类型定义如下:
template <typename _Key, typename _Value>
class BSNode
{
public:
BSNode() : key(), value(), parent(NULL), left(NULL), right(NULL) {}
BSNode(_Key k, _Value v) : key(k), value(v), parent(NULL), left(NULL), right(NULL) {}
BSNode *parent;
BSNode *left;
BSNode *right;
_Key key;
_Value value;
};
结点中除了包含指向左孩子和右孩子的指针,还包含指向双亲的指针,若某个孩子结点不存在,则相应的指针为 NULL,根结点的 parent 指针为 NULL。
二叉查找树类型定义如下:
#ifndef __BSTREE_H__
#define __BSTREE_H__
#include <cstdlib>
#include <vector>
#include <stack>
#include <functional>
#include <cassert>
template <typename _Key, typename _Value, typename _Compare = std::less<_Key> >
class BSTree
{
public:
BSTree() : node_count(0), key_compare(), root(NULL) {}
BSTree(_Compare _compare) : node_count(0), key_compare(_compare), root(NULL) {}
~BSTree() {}
/** @name APIs of BSTree. */
///@{
bool empty() { return node_count == 0 ? true : false; }
size_t size() { return node_count; }
BSNode<_Key, _Value>* find(const _Key& k);
BSNode<_Key, _Value>* successor(BSNode<_Key, _Value> *p);
BSNode<_Key, _Value>* predecessor(BSNode<_Key, _Value> *p);
/** @brief insert a node. */
BSNode<_Key, _Value>* insert(const _Key& k, const _Value& v);
/** @brief erase a node by key only need adjust points[predecessor edition]. */
void erase(const _Key& k);
/** @brief erase a node by point only need adjust points[predecessor edition]. */
void erase(BSNode<_Key, _Value> *node);
/** @brief erase a node by key only need adjust points[successor edition]. */
void erase2(const _Key& k);
/** @brief erase a node by point only need adjust points[successor edition]. */
void erase2(BSNode<_Key, _Value> *node);
/** @brief erase a node by key need value copying[predecessor edition]. */
void erase3(const _Key& k);
/** @brief erase a node by key need value copying[successor edition]. */
void erase4(const _Key& k);
/** @brief clear all nodes of BSTree. */
void clear();
///@}
/** @name Traverse methods of BSTree. */
///@{
void preOrderTraverse(std::vector<BSNode<_Key, _Value>* >& vec);
void inOrderTraverse(std::vector<BSNode<_Key, _Value>* >& vec);
void postOrderTraverse(std::vector<BSNode<_Key, _Value>* >& vec);
///@}
private: /* internal functions */
BSNode<_Key, _Value>* _minimum(BSNode<_Key, _Value> *p);
BSNode<_Key, _Value>* _maximum(BSNode<_Key, _Value> *p);
private: /* data */
size_t node_count;
_Compare key_compare;
BSNode<_Key, _Value> *root;
};
#endif
该实现将二叉查找树泛化成了模板形式,关键字和存储值以及关键字的次序比较谓词都作为模板参数,其中次序比较谓词默认使用 std::less<> 算子,类 BSTree 使用 node_count 记录树中当前结点的个数,其实例化的对象只包含指向根结点的指针 root,其他结点均通过根结点间接访问,由于采用了次序比较谓词,其比较判断两个关键字是否相等的内在含义是 ” equivalence ” 而非 ” equality “,此两者的区别可参考 Scott Meyers 所著《Effective STL》一书中的 Item 19,因此该 BSTree 的实现不允许树中存在有着相同 key 的结点。
对于二叉查找树,最简单的操作莫过于查找其中关键字最小或最大的结点,对于关键字最小的结点,只需从根结点一路往左,沿着各结点的 left 指针查找下去,直到遇到 left 指针域为 NULL 的结点为止,该结点即为关键字最小的结点,下面的函数 _minimum() 返回指向结点 p 的子树中关键字最小结点的指针,要查找整棵树中关键字最小的结点时只需令 p 为 root 即可:
template <typename _Key, typename _Value, typename _Compare>
BSNode<_Key, _Value>* BSTree<_Key, _Value, _Compare>::_minimum(BSNode<_Key, _Value> *p)
{
while (p->left != NULL) p = p->left;
return p;
}
同理,查找关键字最大的结点只需从根结点一路往右,沿着各结点的 right 指针查找下去,直到遇到 right 指针域为 NULL 的结点为止:
template <typename _Key, typename _Value, typename _Compare>
BSNode<_Key, _Value>* BSTree<_Key, _Value, _Compare>::_maximum(BSNode<_Key, _Value> *p)
{
while (p->right != NULL) p = p->right;
return p;
}
正如二叉查找树的命名所示,其最常见的操作就是根据关键字查找树中对应的结点并返回指向对应待查找结点的指针,若不存在这样的结点则返回 NULL,find 函数从根结点开始进行查找,并沿着树下降,对碰到的每个结点 p,比较 k 和 p->key,根据比较结果决定继续查找 p 的左子树还是右子树,直至结点 p 为 NULL 或是比较结果相同为止,随后返回 p:
template <typename _Key, typename _Value, typename _Compare>
BSNode<_Key, _Value>* BSTree<_Key, _Value, _Compare>::find(_Key k)
{
if (root == NULL) return NULL;
BSNode<_Key, _Value> *p = root;
while (p != NULL)
{
if (key_compare(k, p->key)) // k < p->key
p = p->left;
else if (key_compare(p->key, k)) // k > p->key
p = p->right;
else // k == p->key
break;
}
return p;
}
根据二叉查找树的性质,可以得知其中序遍历序列是有序序列,因此给定一个二叉查找树中的结点,有时需要找出它在中序遍历下的前趋或是后继。在给出这两个算法之前,先回顾下二叉树的三种遍历算法的非递归实现,在这三种遍历的实现中,依次将访问的结点 push_back 进 std::vector 中,首先来看先序遍历算法:
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::preOrderTraverse(std::vector<BSNode<_Key, _Value>* >& vec)
{
if (node_count == 0) return;
vec.reserve(node_count);
std::stack<BSNode<_Key, _Value>* > S;
BSNode<_Key, _Value> *p = root;
while (p != NULL || !S.empty())
{
if (p != NULL)
{
vec.push_back(p);
S.push(p);
p = p->left;
}
else
{
p = S.top();
S.pop();
p = p->right;
}
}
}
算法使用栈 S 暂存访问过的结点,以便在访问了该结点的左子树之后还能够取得该结点以继续访问其右子树,算法执行至栈 S 为空为止,此时表明所有结点均已被访问。中序遍历算法的非递归实现与先序遍历非常相似,差别只在于访问结点的时刻不同,先序遍历是在结点入栈的时候访问,而中序遍历是在结点出栈的时候访问:
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::inOrderTraverse(std::vector<BSNode<_Key, _Value>* >& vec)
{
if (node_count == 0) return;
vec.reserve(node_count);
std::stack<BSNode<_Key, _Value>* > S;
BSNode<_Key, _Value> *p = root;
while (p != NULL || !S.empty())
{
if (p != NULL)
{
S.push(p);
p = p->left;
}
else
{
p = S.top();
S.pop();
vec.push_back(p);
p = p->right;
}
}
}
在给出后序遍历算法的非递归形式之前,顺便先给出二叉查找树的 clear 算法,因为其实现完全可以套用中序遍历算法的非递归形式,结点的删除顺序即为中序遍历下结点的访问顺序,只是在执行 p = p->right; 语句之前需要另外使用一个指针 q 来暂存要被删除的结点:
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::clear()
{
if (node_count == 0) return;
std::stack<BSNode<_Key, _Value>* > S;
BSNode<_Key, _Value> *p = root, *q = NULL;
while (p != NULL || !S.empty())
{
if (p != NULL)
{
S.push(p);
p = p->left;
}
else
{
p = S.top();
S.pop();
q = p;
p = p->right;
delete q;
}
}
root = NULL;
node_count = 0;
}
下面来详细阐述后序遍历算法的非递归实现,因为需要保证双亲结点在其孩子结点都已被访问之后才能被访问,因此需要一个 prev 指针来指向之前刚刚被访问过的那个结点,只有当刚刚访问过的那个结点是当前待访问结点的孩子结点的时候或是当前结点是叶子结点的时候才能被访问,否则先将当前待访问结点的右孩子先入栈,随后将当前待访问结点的左孩子后入栈,这保证了出栈时的顺序是左孩子在前右孩子在后,而访问结点的时刻就在结点出栈时,随后置 prev 指针指向当前已刚刚访问的结点:
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::postOrderTraverse(std::vector<BSNode<_Key, _Value>* >& vec)
{
if (node_count == 0) return;
vec.reserve(node_count);
std::stack<BSNode<_Key, _Value>* > S;
BSNode<_Key, _Value> *prev = NULL, *cur = NULL;
S.push(root);
while (!S.empty())
{
cur = S.top();
/* visit cur when it is a leaf node or its childs have been visited */
if ( (cur->left == NULL && cur->right == NULL) ||
prev != NULL && (prev == cur->left || prev == cur->right) )
{
vec.push_back(cur);
S.pop();
prev = cur;
}
else
{
/* push() right child first, left child second, so left child comes first when pop() */
if (cur->right != NULL) S.push(cur->right);
if (cur->left != NULL) S.push(cur->left);
}
}
}
好!在回顾了二叉树的遍历算法之后,来看如何查找 BSTree 中一个结点在中序遍历顺序下它的后继,对于给定结点 p 存在两种情况,一种是 p 的右子树非空,则其后继就是右子树中关键字最小的那个结点,另一种是 p 的右子树为空,则 p 的后继是 q 的所有祖先结点中满足 q 的左孩子也是 p 的祖先结点的最低祖先结点,为找到 q,应从 p 沿着 parent 指针域向上查找,直至遇到某个是其双亲结点的左孩子的结点时为止,q 就是该结点的双亲结点:
template <typename _Key, typename _Value, typename _Compare>
BSNode<_Key, _Value>* BSTree<_Key, _Value, _Compare>::successor(BSNode<_Key, _Value> *p)
{
assert( p != NULL );
if (p->right != NULL)
return _minimum(p->right);
BSNode<_Key, _Value> *q = p->parent;
while (q != NULL && q->right == p)
{
p = q;
q = q->parent;
}
return q;
}
寻找给定结点 p 的前趋的算法与上述寻找后继的算法对称,在此直接给出不再赘述:
template <typename _Key, typename _Value, typename _Compare>
BSNode<_Key, _Value>* BSTree<_Key, _Value, _Compare>::predecessor(BSNode<_Key, _Value> *p)
{
assert( p != NULL );
if (p->left != NULL)
return _maximum(p->left);
BSNode<_Key, _Value> *q = p->parent;
while (q != NULL && q->left == p)
{
p = q;
q = q->parent;
}
return q;
}
讲述完这些基本的操作之后,下面来细看二叉查找树两个最重要的操作:插入和删除。
insert
由于插入操作稍微简单先,那么就从简单的开始,插入操作的函数接受一对 key 和 value 的参数,若树中已存在关键字与传入的关键字相等的结点,则直接返回指向该结点的指针,否则根据传入的形参创建一个新结点 node,将其插入到树中的合适位置后再返回指向该新创建结点的指针,根据新结点的 key 与待插入位置双亲结点的 key 的比较结果来决定是将新结点作为左孩子插入还是右孩子插入,额外需要注意的是树为空的情况,这时只需让根结点指针 root 指向新创建结点即可:
template <typename _Key, typename _Value, typename _Compare>
BSNode<_Key, _Value>* BSTree<_Key, _Value, _Compare>::insert(_Key k, _Value v)
{
BSNode<_Key, _Value> *p = root, *q = NULL;
while (p != NULL)
{
q = p;
if (key_compare(k, p->key)) // k < p->key
p = p->left;
else if (key_compare(p->key, k)) // k > p->key
p = p->right;
else // k == p->key
return p;
}
BSNode<_Key, _Value> *node = new BSNode<_Key, _Value>(k, v);
node->parent = q;
if (q == NULL) // before insert, tree is empty
root = node;
else if (key_compare(k, q->key)) // k < q->key
q->left = node;
else
q->right = node;
++node_count;
return node;
}
上述插入算法在树为空的时候,p = root 语句执行过后 p 是 NULL,因此不会进行 while 循环,因此 q 赋给 node->parent 的时候仍是 NULL,刚好此时的 node 应当成为根结点,根结点的 parent 指针域为 NULL,算法执行与预期一致。
erase
最后来详细讨论从二叉查找树中删除给定结点 node 的三种情况:1. 结点 node 是叶子结点,则只需调整其双亲节点的指针域,直接删除 node 即可;2. 结点 node 有一个孩子结点,则可以将其双亲结点和其孩子结点相互链接起来,随后删除 node 即可;3. 结点 node 有两个孩子结点,则相对比较麻烦些,下面给出两种解决方案的算法:
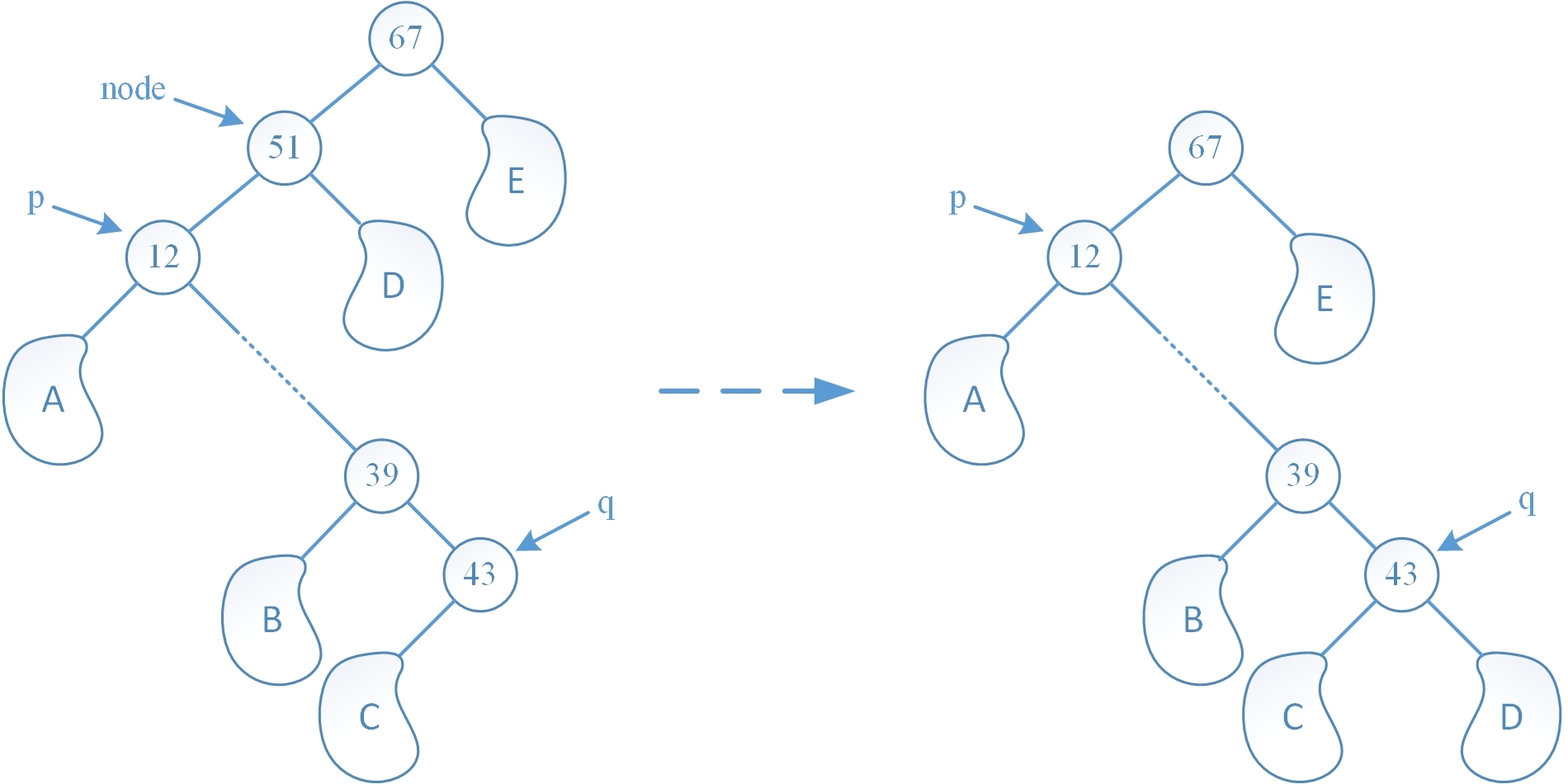
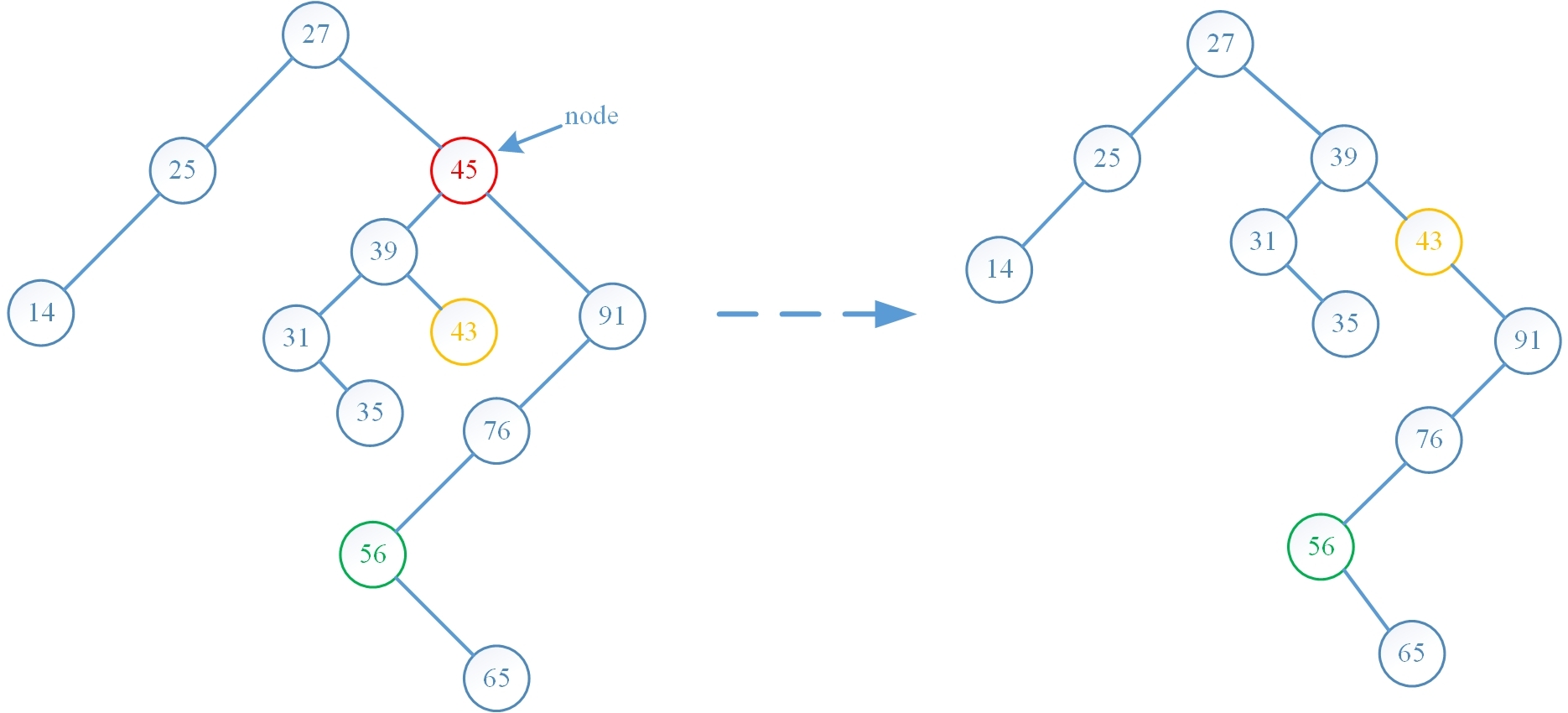
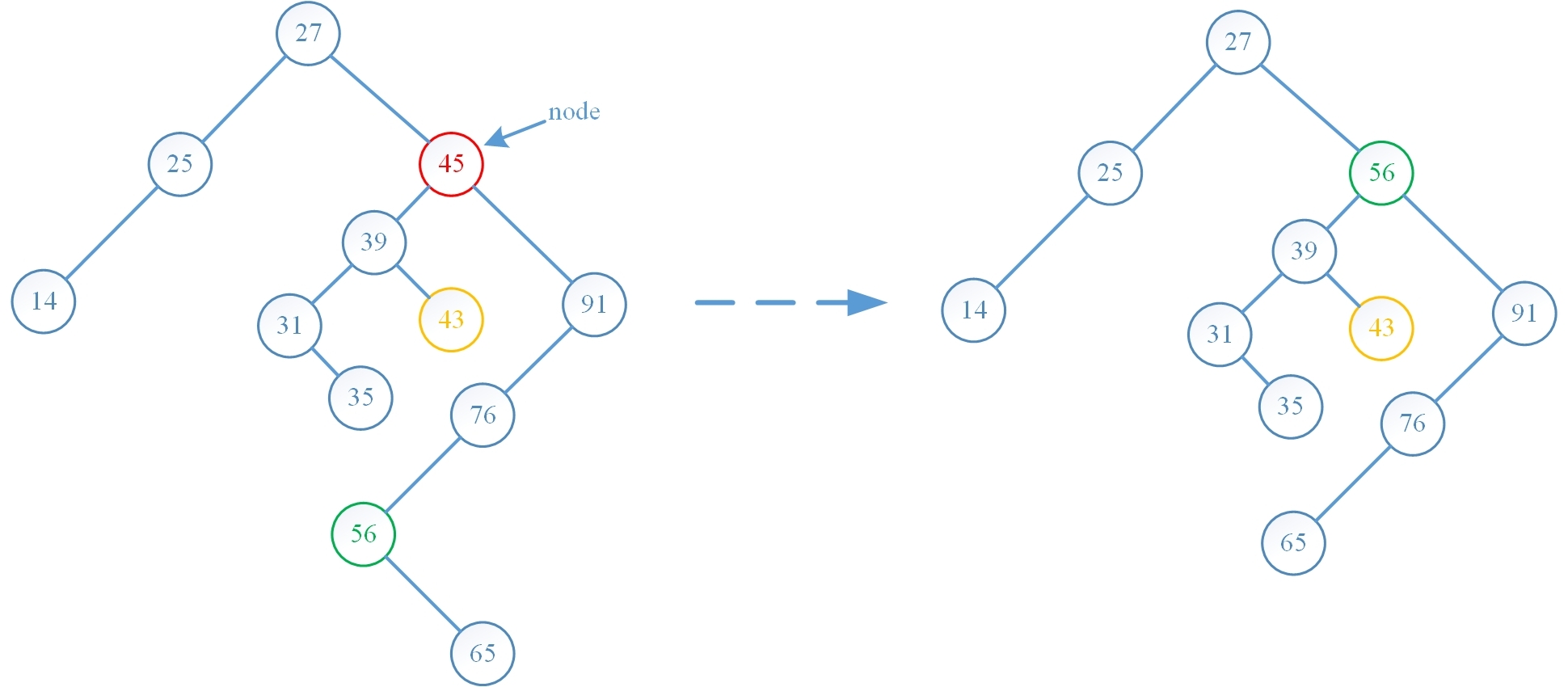
第一种算法是先找到 node 的直接前趋结点 q,则结点 q 一定没有右孩子结点,否则结点 q 的后继一定在其右子树中,这与它的后继是 node 矛盾,随后先将 node 的左孩子 p 和 node 的双亲相互链接起来,然后将 q 的右孩子指针指向 node 的右孩子结点,从而 node 的整棵右子树就成为了 q 的右子树,随后删除 node 结点,这种算法只需要调整指针域即可,效率很高(但是这种算法在二叉平衡树中似乎不太可行,因为整棵树的结构调整地太厉害了,导致过多结点的平衡因子需要调整),算法的演示图如下:
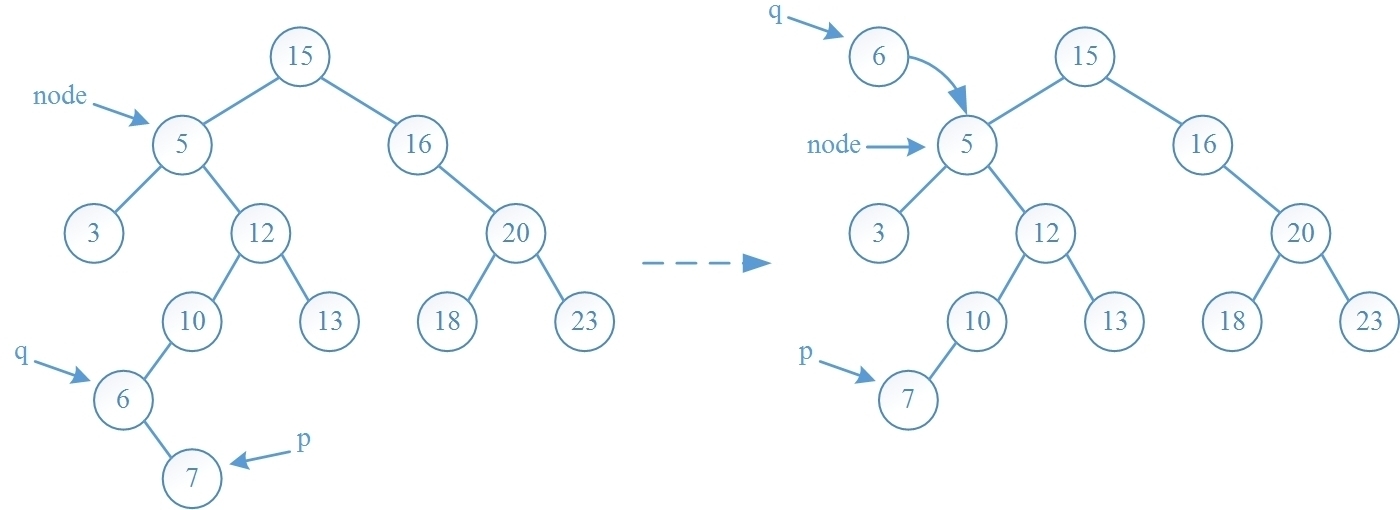
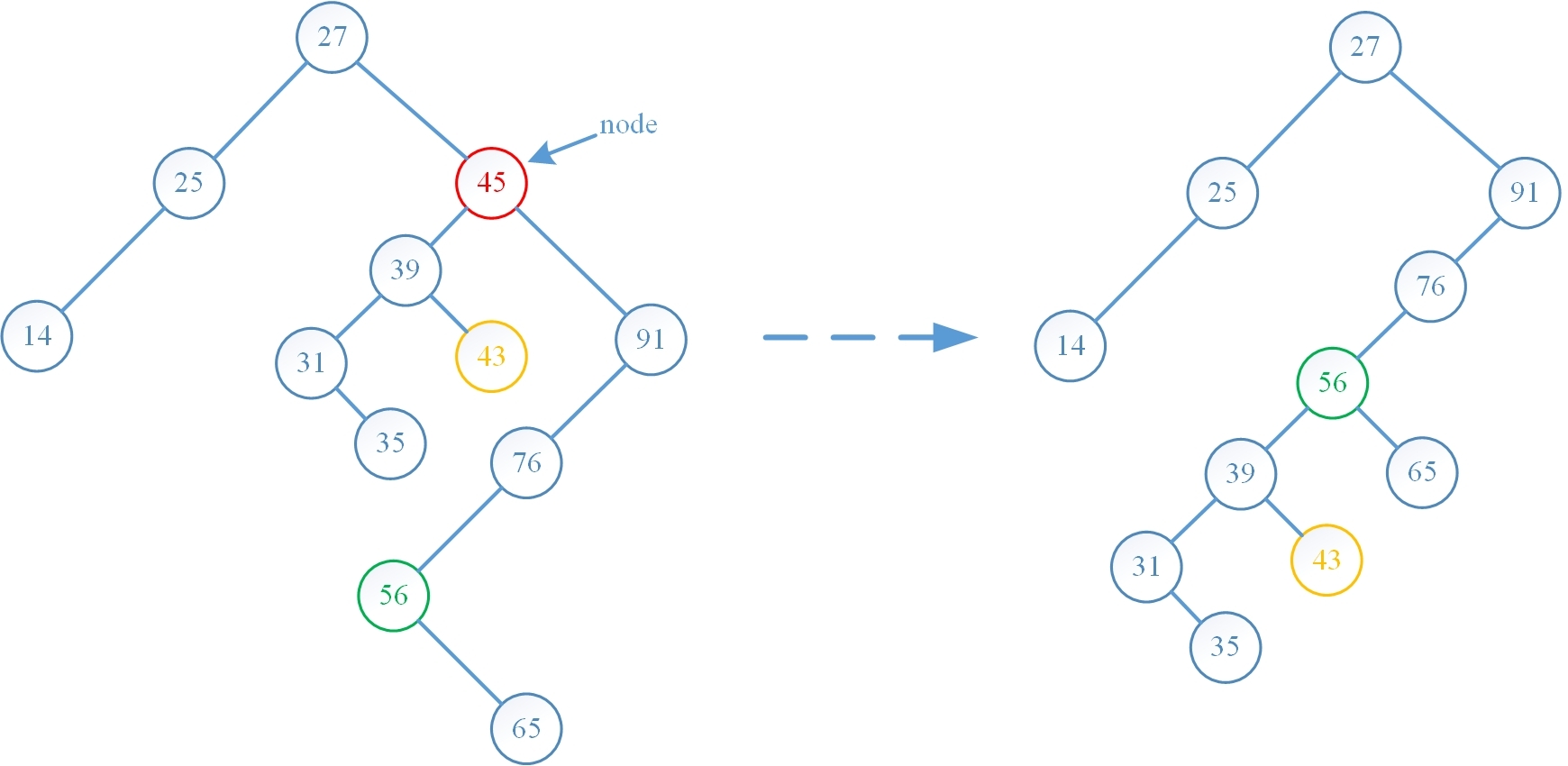
第二种算法是先找到 node 的直接后继结点 q,则结点 q 一定没有左孩子,否则结点 q 的前趋一定在其左子树中,这与它的前趋是 node 矛盾,随后用 q 去替代 node,再从树中把 q 删去即可,算法的演示图如下(此例来源于《算法导论》):
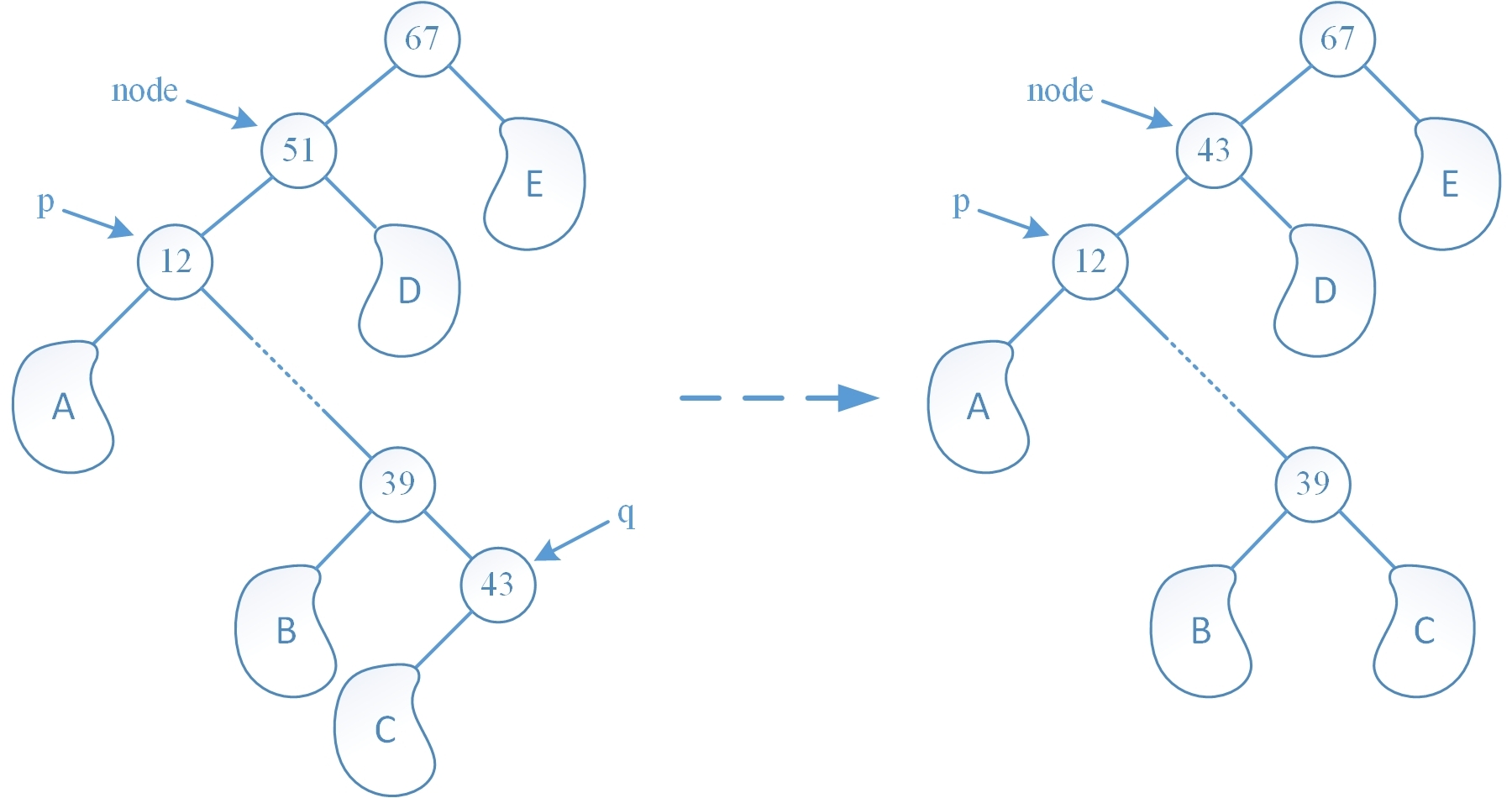
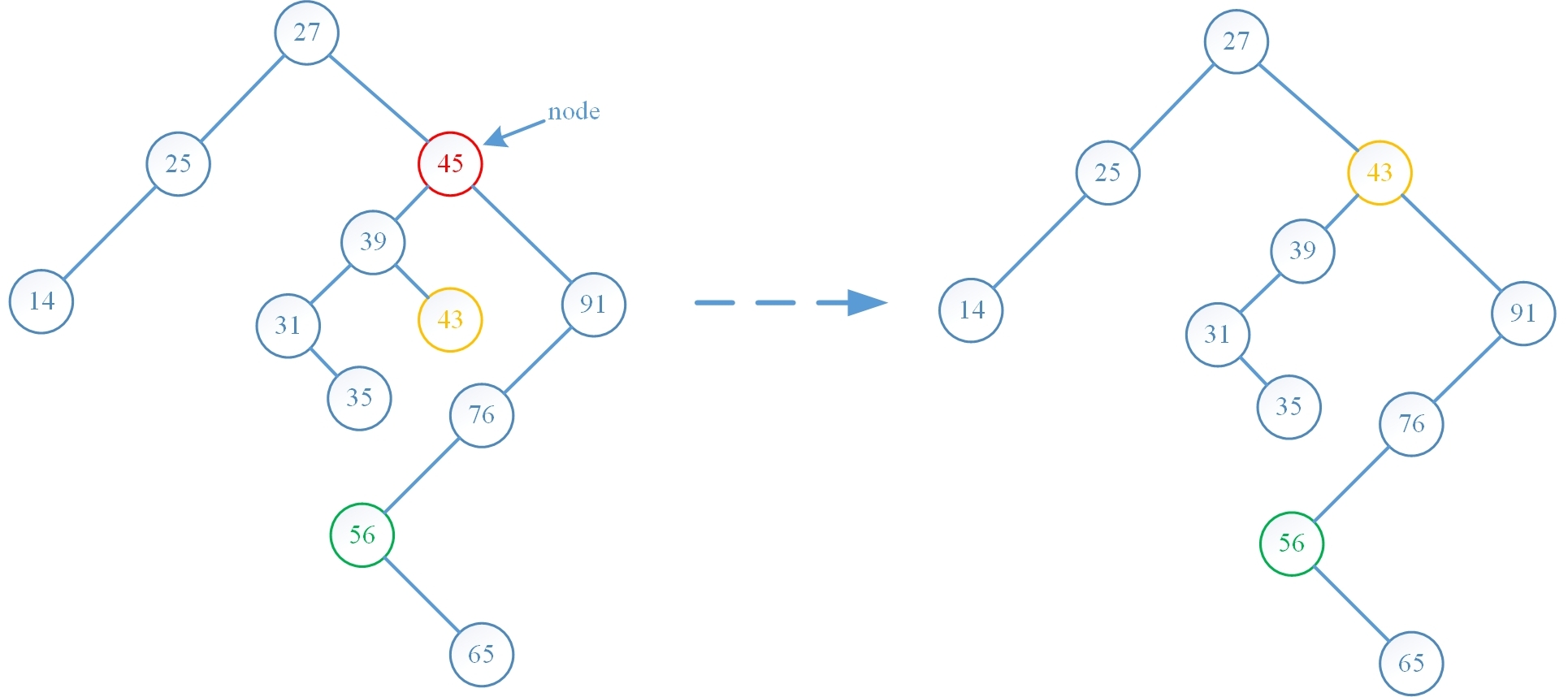
注意第一个算法也可采用把待删除结点的左子树传给其直接后继的方式,第二个算法也可采用直接前趋去替代待删除结点方式,譬如下图就是第二个算法采用了直接前趋去代替待删除结点的方式(可以将此图与第一种算法做个比较,可以看出这种算法对树结构的改变是最小的):
下面给出了这两种删除节点算法的四种实现(同一种算法的两种实现方式的代码基本是对称):
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::erase(const _Key& k)
{
BSNode<_Key, _Value> *node = find(k);
erase(node);
}
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::erase(BSNode<_Key, _Value> *node)
{
if (node == NULL) return;
BSNode<_Key, _Value> *p = NULL, *q = NULL;
if (node->left == NULL || node->right == NULL)
q = node;
else
q = predecessor(node); // q has no right child
/* adjust parent-point of node's child and child-point of node's parent */
if (node->left != NULL)
p = node->left;
else
p = node->right;
if (p != NULL)
p->parent = node->parent;
if (node->parent == NULL) // root is the node to be deleted
root = p;
else if (node->parent->left == node)
node->parent->left = p;
else
node->parent->right = p;
/* make the right child of node to be the right child of its predecessor */
if (q != node)
{
q->right = node->right;
node->right->parent = q;
}
delete node;
--node_count;
}
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::erase2(const _Key& k)
{
BSNode<_Key, _Value> *node = find(k);
erase2(node);
}
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::erase2(BSNode<_Key, _Value> *node)
{
if (node == NULL) return;
BSNode<_Key, _Value> *p = NULL, *q = NULL;
if (node->left == NULL || node->right == NULL)
q = node;
else
q = successor(node); // q has no left child
/* adjust parent-point of node's child and child-point of node's parent */
if (node->right != NULL)
p = node->right;
else
p = node->left;
if (p != NULL)
p->parent = node->parent;
if (node->parent == NULL) // root is the node to be deleted
root = p;
else if (node->parent->left == node)
node->parent->left = p;
else
node->parent->right = p;
/* make the left child of node to be the left child of its successor */
if (q != node)
{
q->left = node->left;
node->left->parent = q;
}
delete node;
--node_count;
}
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::erase3(const _Key& k)
{
BSNode<_Key, _Value> *node = find(k);
if (node == NULL) return;
BSNode<_Key, _Value> *p = NULL, *q = NULL;
if (node->left == NULL || node->right == NULL)
q = node;
else
q = predecessor(node); // q has no right child
/* q is the node to be deleted, make the parent-point of q's child to q's parent */
if (q->left != NULL)
p = q->left;
else
p = q->right;
if (p != NULL)
p->parent = q->parent;
/* q is the node to be deleted, make the child-point of q's parent to q's child */
if (q->parent == NULL) // root is the node to be deleted
root = p;
else if (q->parent->left == q)
q->parent->left = p;
else
q->parent->right = p;
/* make node replaced by its predecessor */
if (q != node)
{
node->key = q->key;
node->value = q->value;
}
delete q;
--node_count;
}
template <typename _Key, typename _Value, typename _Compare>
void BSTree<_Key, _Value, _Compare>::erase4(_Key k)
{
BSNode<_Key, _Value> *node = find(k);
if (node == NULL) return;
BSNode<_Key, _Value> *p = NULL, *q = NULL;
if (node->left == NULL || node->right == NULL)
q = node;
else
q = successor(node); // q has no left child
/* q is the node to be deleted, make the parent-point of q's child to q's parent */
if (q->left != NULL)
p = q->left;
else
p = q->right;
if (p != NULL)
p->parent = q->parent;
/* q is the node to be deleted, make the child-point of q's parent to q's child */
if (q->parent == NULL) // root is the node to be deleted
root = p;
else if (q->parent->left == q)
q->parent->left = p;
else
q->parent->right = p;
/* make node replaced by its successor */
if (q != node)
{
node->key = q->key;
node->value = q->value;
}
delete q;
--node_count;
}
test
对类 BSTree 完整的测试代码如下:
#include "BSTree.h"
#include <iostream>
using std::cout;
using std::endl;
template <typename _Key, typename _Value>
void printTraverseResult(std::vector<BSNode<_Key, _Value>* >& v)
{
for (size_t i = 0; i < v.size(); ++i)
cout << v[i]->key << ' ';
cout << endl;
}
void fillBSTree(BSTree<int, double>& bsTree)
{
bsTree.insert(27, 3.23);
bsTree.insert(45, 1.34);
bsTree.insert(91, 8.36);
bsTree.insert(39, 9.73);
bsTree.insert(25, 7.18);
bsTree.insert(14, 7.51);
bsTree.insert(76, 8.13);
bsTree.insert(56, 4.16);
bsTree.insert(65, 2.86);
bsTree.insert(31, 1.01);
bsTree.insert(43, 5.69);
bsTree.insert(35, 4.97);
}
int main(int argc, char *argv[])
{
cout << "========== test BSTree ==========\n";
BSTree<int, double> bsTree;
std::vector<BSNode<int, double>* > inOrderResult, preOrderResult, postOrderResult;
fillBSTree(bsTree);
cout << "test BSTree::erase(): " << endl;
bsTree.erase(45);
bsTree.inOrderTraverse(inOrderResult);
bsTree.preOrderTraverse(preOrderResult);
bsTree.postOrderTraverse(postOrderResult);
cout << "InOrder: "; printTraverseResult(inOrderResult);
cout << "PreOrder: "; printTraverseResult(preOrderResult);
cout << "PostOrder: "; printTraverseResult(postOrderResult);
inOrderResult.clear();
preOrderResult.clear();
postOrderResult.clear();
bsTree.clear(); // clear the bsTree
fillBSTree(bsTree);
cout << "test BSTree::erase2(): " << endl;
bsTree.erase2(45);
bsTree.inOrderTraverse(inOrderResult);
bsTree.preOrderTraverse(preOrderResult);
bsTree.postOrderTraverse(postOrderResult);
cout << "InOrder: "; printTraverseResult(inOrderResult);
cout << "PreOrder: "; printTraverseResult(preOrderResult);
cout << "PostOrder: "; printTraverseResult(postOrderResult);
inOrderResult.clear();
preOrderResult.clear();
postOrderResult.clear();
bsTree.clear(); // clear the bsTree
fillBSTree(bsTree);
cout << "test BSTree::erase3(): " << endl;
bsTree.erase3(45);
bsTree.inOrderTraverse(inOrderResult);
bsTree.preOrderTraverse(preOrderResult);
bsTree.postOrderTraverse(postOrderResult);
cout << "InOrder: "; printTraverseResult(inOrderResult);
cout << "PreOrder: "; printTraverseResult(preOrderResult);
cout << "PostOrder: "; printTraverseResult(postOrderResult);
inOrderResult.clear();
preOrderResult.clear();
postOrderResult.clear();
bsTree.clear(); // clear the bsTree
fillBSTree(bsTree);
cout << "test BSTree::erase4(): " << endl;
bsTree.erase4(45);
bsTree.inOrderTraverse(inOrderResult);
bsTree.preOrderTraverse(preOrderResult);
bsTree.postOrderTraverse(postOrderResult);
cout << "InOrder: "; printTraverseResult(inOrderResult);
cout << "PreOrder: "; printTraverseResult(preOrderResult);
cout << "PostOrder: "; printTraverseResult(postOrderResult);
bsTree.clear(); // clear the bsTree
priorityQ.clear();
return 0;
}
程序运行的输出结果为:
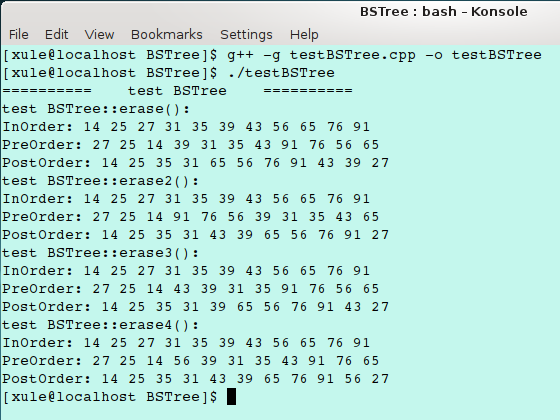
下面按顺序将四种实现方式 erase 操作前后的树结构对比图绘制出来,可以看出算法运行结果与预期是一致的:
nonstd::priority_queue
由于二叉查找树是有序结构,最左端的结点就是树中关键字次序最先的结点,因此可以作为优先队列的一种实现方式,不过 std::priority_queue 是使用二叉堆实现的,由于二叉堆只需保证根结点是关键字次序最先的结点,不用保证所有结点是有序的,条件宽松些,因此使用二叉查找树来实现的优先队列的性能会比使用二叉堆来实现稍微差些,不废话,上代码,只需将 BSTree 类对象作为 nonstd::priority_queue 类的数据成员就好:
namespace nonstd
{
/**
* @brief std::priority_queue is made up with heap, while nonstd::priority_queue is made up with binary search tree.
*/
template <typename _K, typename _V, typename _C = std::less<_K> >
class priority_queue
{
public:
typedef BSNode<_K, _V>* iterator;
typedef _C key_compare;
priority_queue() : _M_t(), compare(), _left_most(NULL) {}
explicit priority_queue(const _C& __comp) : _M_t(__comp), compare(__comp), _left_most(NULL) {}
~priority_queue() { clear(); }
/** @name APIs of nonstd::priority_queue. */
///@{
bool empty() { return _M_t.empty(); }
size_t size() { return _M_t.size(); }
const iterator& top() const { return _left_most; }
void push(const _K& k, const _V& v);
void pop();
void erase(const _K& k);
void clear() { _M_t.clear(); _left_most = NULL; }
///@}
private:
priority_queue(const priority_queue&);
priority_queue& operator=(const priority_queue&);
private:
iterator _left_most; ///< pointing to the left most node in the BSTree.
BSTree<_K, _V, _C> _M_t; ///< binary search tree representing nonstd::priority_queue.
key_compare compare; ///< used to judge if point _left_most should be adjusted when insert() or erase() is called.
};
template <typename _K, typename _V, typename _C>
void priority_queue<_K, _V, _C>::push(const _K& k, const _V& v)
{
iterator node = _M_t.insert(k, v);
if (_M_t.size() == 1)
_left_most = node;
else
{
if (compare(k, _left_most->key)) // k < _left_most->key
_left_most = _M_t.predecessor(_left_most);
}
}
template <typename _K, typename _V, typename _C>
void priority_queue<_K, _V, _C>::pop()
{
iterator p = _left_most;
_left_most = _M_t.successor(_left_most);
_M_t.erase(p);
}
template <typename _K, typename _V, typename _C>
void priority_queue<_K, _V, _C>::erase(const _K& k)
{
if (_M_t.empty()) return;
if (!compare(_left_most->key, k) && !compare(k, _left_most->key)) // k == _left_most->key
{
iterator p = _left_most;
_left_most = _M_t.successor(_left_most);
_M_t.erase(p);
}
else
_M_t.erase(k);
}
} /* namespace nonstd */
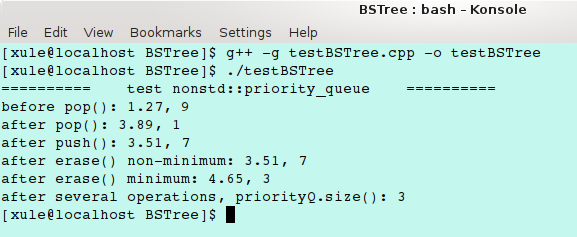
测试代码如下:
int main(int argc, char *argv[])
{
cout << "========== test nonstd::priority_queue ==========\n";
nonstd::priority_queue<ClientKey, int, ClientKeyCmp> priorityQ;
priorityQ.push(ClientKey(8.42), 5);
priorityQ.push(ClientKey(4.65), 3);
priorityQ.push(ClientKey(3.89), 1);
priorityQ.push(ClientKey(7.52), 6);
priorityQ.push(ClientKey(1.27), 9);
nonstd::priority_queue<ClientKey, int, ClientKeyCmp>::iterator iter = priorityQ.top();
cout << "before pop(): " << iter->key.cli_key << ", " << iter->value << endl;
priorityQ.pop();
iter = priorityQ.top();
cout << "after pop(): " << iter->key.cli_key << ", " << iter->value << endl;
priorityQ.push(ClientKey(3.51), 7);
iter = priorityQ.top();
cout << "after push(): " << iter->key.cli_key << ", " << iter->value << endl;
priorityQ.erase(3.89);
iter = priorityQ.top();
cout << "after erase() non-minimum: " << iter->key.cli_key << ", " << iter->value << endl;
priorityQ.erase(3.51);
iter = priorityQ.top();
cout << "after erase() minimum: " << iter->key.cli_key << ", " << iter->value << endl;
cout << "after several operations, priorityQ.size(): " << priorityQ.size() << endl;
priorityQ.clear();
return 0;
}
运行结果如下: